多元回归模型
y=β0+β1x1+β2x2+...+βkxk+u
Example:
可以在模型中加入更多的解释变量:
wage=β0+β1educ+β2exper+u
更加灵活的方程形式:
家庭收入(inc)和消费(cons)的关系:
cons=β0+β1inc+β2inc2+u
多元回归方程的推导
总体方程:
yi=β0+β1xi1+β2xi2+...+βkxik+ui
拟合值:
yi^=β0^+β1^xi1+β2^xi2+...+βk^xik
残差:
ui^=yi−yi^=yi−β0^−β1^xi1−β2^xi2−...−βk^xik
最小化残差平方和:
mini=1∑nui^2=mini=1∑n(yi−β0^−β1^xi1−β2^xi2−...−βk^xik)2
一阶条件(分别对βi求导):
∂β0^∂∑i=1nui^2=i=1∑n−2(yi−β0^−β1^xi1−β2^xi2−...−βk^xik)=i=1∑nui^=0
∂β1^∂∑i=1nui^2=i=1∑n−2xi1(yi−β0^−β1^xi1−β2^xi2−...−βk^xik)=i=1∑nxi1ui^=0
同理对于$ \forall k>0$:
i=1∑nxikui^=0
k+1个方程求解k+1个变量。
数值特征:
样本均值点在回归线上
yˉ=β0^+β1^xˉ1+β2^xˉ2+...+βk^xˉk
证明:
i=1∑nui^=i=1∑n(yi−yi^)=0=> yˉ=y^ˉ
再对n个估计式累加再除以n,易得证。
每个自变量和OLS残差之间的样本协方差为零
样本协方差为:
=n−11(i=1∑n(xi1−xˉ)(ui^−u^ˉ))=n−11(i=1∑nxi1ui^−i=1∑nxi1u^ˉ−i=1∑nxˉui^+i=1∑nxˉu^ˉ)=0
*高级计量结果
β^=(X′X)−1X′y
对多元回归排除其他变量的解释
字面上来说,βi是保持其他变量不变时,xi变化对y的影响。而事实上,自变量之间存在或多或少的关联,如x1的变动会导致x2的变动,而x2的变动又会导致y的变动。但我们在衡量x1对y的影响(即β1)时仅仅考虑x1对y的直接影响,通过其他变量间接传导的影响不在考虑之内。
正因如此,多元回归的系数结果通常不等于一元回归,因为多元回归中自变量大概率存在关联性,而多元回归的过程中自动排除了相关变量间接传导的影响。
β1^可以写成另外一个形式:
β1^=∑i=1nr^i12∑i=1nr^i1yi
其中,残差r来自x1对x2,x3,...,xk的回归。
证明:
已知 xi1=x^i1+r^i1,代入原回归的一阶条件得:
i=1∑n(x^i1+r^i1)(yi−β^0−β^1xi1−...−β^kxik)=0
而x^i1是xi2,...,xik的线性函数,故 ∑i=1nx^i1u^i=0,于是:
i=1∑nr^i1(yi−β^0−β^1xi1−...−β^kxik)=0
而 r^i1是残差,故∑i=1nxijr^i1=0,于是:
i=1∑nr^i1(yi−β^1xi1)=0i=1∑nr^i1(yi−β^1(x^i1−r^i1))=0i=1∑nr^i1(yi−β^1r^i1)=0
最终得到:
β1^=∑i=1nr^i12∑i=1nr^i1yi
理解:
因为残差r^i1是xi1中与剩余xj1不相关的部分,故β^1度量了排除其他自变量影响后y与x1的关系。这个结果成为弗里施-沃定理(Frish−Waugh theorem),这种回归方式称为分块回归或偏回归。
拟合优度R2
R2等于yi实际值与其拟合值yi^的相关系数的平方
R2=(corr(yi,yi^))2=(∑i=1n(yi−yˉ)2)(∑i=1n(yi^−y^ˉ)2)(∑i=1n(yi−yˉ)(yi^−y^ˉ))2
证明:
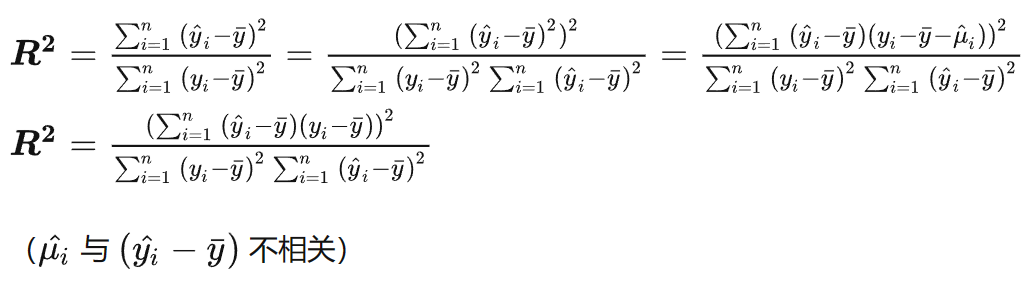
OLS估计量的期望值
经典假设条件
Assumption MLR.1 (线性于参数)
y=β0+β1x1+β2x2+...+βkxk+u
这是对总体模型或真实模型的规范表述
Assumption MLR.2 (随机抽样)
{(xi1,xi2,...,xik,yi):i=1...n}
yi=β0+β1xi1+β2xi2+...+βkxik+ui
该假设控制了单个样本不受其它样本影响。
Assumption MLR.3 (No perfect collinearity不存在完全共线性)
在样本中,没有一个自变量是常数,自变量之间也不存在严格的线性关系(可以有相关性)。
从矩阵来看,如果存在线性关系,就不满秩了,也就没有逆矩阵了。
该假设可以保证存在唯一的OLS估计值
Assumption MLR.4(条件均值为零)
E(ui∣xi1,xi2,...,xik)=0
简单来说,误差项和解释变量是不相关的。
具体意味着,影响y的其他因素总体上与xi1,xi2,...,xik不相关。
定理3.1 无偏性
由MLR.1−MLR.4可以推导出:
E(βj^)=βj
初等代数证明:
我们已知:
β1^=∑i=1nr^i12∑i=1nr^i1yi
将总体方程代入:
yi=β0+β1xi1+β2xi2+...+βkxik+ui
可得:
β1^=β1+∑i=1nr^i12∑i=1nr^i1ui
考虑到r^i1只是样本自变量的函数,于是:
E(β^1∣X)=β1+∑i=1nr^i12∑i=1nr^i1E(ui∣X)=0
得证。
矩阵证明:
暂时略,后续补充。
实证研究中,有些情况可能会影响我们获得无偏估计值,如:
哪些情况会影响我们获得无偏估计值?
遗漏变量:
假设真实世界中:
y=β0+β1x1+β2x2+u
但由于种种因素,导致我们忽略了x2的存在,仅以为:
y=α0+α1x1+w
x2某种程度上变成了w的一部分。
而x2与x1之间存在关系:
x2=δ0+δ1x1+v
则:
y=β0+β1x1+β2(δ0+δ1x1+v)+u=(β0+β2δ0)+(β1+β2δ1)x1+(β2v+u)
这导致我们的估计值为:
α1=β1+β2δ1
与真实结果产生了偏差。而估计值由两部分构成,一部分是x1本身的影响,另一部分是x1通过影响x2间接对y产生的影响。
如果结果不产生偏差,则说明:
δ1=0 或 β2=0
即,要么样本中x1和x2不相关,要么x2本身对y没有影响。
在回归模型中加入自变量的过程某种程度上可以理解为不断控制变量的过程,例如,在衡量x1的影响时,模型自动排除了x2,x3....xn的影响。
如果x2只与y有关而与x1无关,则不会的β1的无偏性造成影响,只是由于遗漏x2导致误差项中的σ2提升,进而会提高Var(β1)。(当然Rj2也会有所变化,但因为x2与x1无关,所以Rj2变化不大)因此,一般认为x2也要加入回归。
OLS统计量的方差
Assumption MLR.5 (同方差性)
Var(ui∣xi1,xi2,...,xik)=σ2
给定任意解释变量值,误差u都具有相同的方差。
由MLR.5:
Var(y∣X)=σ2
即给定x,y的方差不取决于自变量的值。
定理3.2 OLS斜率估计量的抽样方差
根据假设MLR.1−MLR.5(高斯-马尔科夫假定),可以推导到:
Var(βj^)=SSTj(1−Rj2)σ2 ,j=1,2...k
其中:
SSTj=i=1∑n(xij−xˉj)2
SSTj用来衡量自变量xj的样本波动性
Rj2是一个拟合优度,来自一个回归模型,其中因变量为xj,自变量是其他解释变量(包括常数项),其本质上是在衡量其他x与xj的相关程度。
xj=α0+α1x1+...+αj−1xj−1+αj+1xj+1+...+αkxk+v
证明
Var(β1^)=Var(∑i=1nr^i12∑i=1nr^i1yi)=(∑i=1nr^i12)2∑i=1nr^i12Var(ui∣X)=(∑i=1nr^i12)2∑i=1nr^i12σ2=∑i=1nr^i12σ2
因为∑i=1nr^i12是x1对x2,...,xk回归的残差平方和,故:
i=1∑nr^i12=SST1(1−R12)
得证。
从上述公式来看,Var(βj^)受三个部分影响。
-
σ2越大,方差中“噪声”越大,导致方差越大
-
xj的总样本波动越大,跨度越大,结果越准确,β的方差就越小
-
如果R2很大,代表着相关性很大,代表着很多信息由于相关性而产生了重叠,“有用”的信息越少,方差越大。
多重共线性
两个或多个自变量之间高度(但不完全)相关被称为多重共线性(multicollinearity)
解决多重共线性的方法
1、把一些变量加总起来(如各项支出)
2、把某些变量剔除(装看不见嘿嘿),尽管可能会导致变量遗漏问题。
3、构建方差膨胀因子(variance inflation factors)
VIFj=1−Rj21
常见的指标是 VIF 不能大于10
误设模型中的方差
回归模型中是否添加某特定变量的判断标准。
真实的回归模型:
y=β0+β1x1+β2x2+u
回归模型1:
y^=β0^+β1^x1+β2^x2
回归模型2:
y~=β0~+β1~x1
通过计算可得:
Var(β1^)=SST1(1−R12)σ2
Var(β1~)=SST1σ2
可以看到,Var(β1^)>Var(β1~)(其实不对,因为两个式子中的σ不一样),可见增加自变量会增加估计量的去方差(至少不会减少)。
考虑如下情况:
若 β2=0 ,则:
E(β1^)=β1 E(β1~)=β1Var(β1^)>Var(β1~)
这告诉我们不要把无关变量放进模型,无关变量只会加剧共线性问题。
若 β2=0 ,则:
E(β1^)=β1 E(β1~)=β1Var(β1^)>Var(β1~)
这时候就需要进行取舍(trade off),经济学中一般认为无偏性更加重要一点
估计误差项的方差
我们构造一个估计量:
σ2^=n−k−1∑i=1nui^2
n−k−1为残差变动的自由度,即残差可以自由取值的个数,即当我们给定残差中的n−k−1个,余下的k+1个便是已知的,k+1个限制来自于最小二乘法时k+1个限制条件。
定理3.3 σ2的无偏估计
由假设MLR.1−MLR.5,我们有:
E(σ2^)=σ2
证明:
矩阵证明,暂时略,后续补。
σ^ 称为回归标准误($standard\ error\ of\ the\ regression $),简称 $ SER $,是误差项标准差的估计值。
βj^的标准差($standard\ deviation $)为:
sd(βj^)=Var(βj^)=SSTj(1−Rj2)σ
由于我们无法获得σ的真实值,故我们需要使用估计值σ^进行替换,则:
βj^的标准误(standard error)为:
se(βj^)=Var^(βj^)=SSTj(1−Rj2)σ^
标准误是一个随机变量,来源于样本,当样本确定时,标准误也随之确定。
值得注意的是,标准误的依赖于Var(βj^)的公式,而该公式又依赖与同方差假定MLR.5。所以如果误差出现异方差性,不会导致βj^的偏误,却会导致对Var(βj^)的错误估计。
我们可以对标准误进行变形,得到:
se(βj^)=n sd(xj)(1−Rj2)σ^
其中,sd(xj)=n−1∑i=1n(xij−xˉj)2,是样本标准差。
se(βj^)中的各部分都随n的变动而变动,但是n越来越大时,除n外各部分均会趋于常数。由此我们知道,标准误大致以$1/ \sqrt{n} $的速率收敛到0。
OLS的有效性:高斯-马尔科夫定理(The Gauss−Markov Theorem)
我们需要判断普通最小二乘法(OLS)是不是好的,方法是与其他估计值进行比较。我们在比较OLS和其他方法估计值时,我们只比较线性估计值,即:
βj~=i=1∑nωijyi
其中,wij是自变量x的函数。
定理3.4
在假定MLR.1−MLR.5下,β0^,β1^,...βk^是β0,β1,...,βk的最优线性无偏估计量(BLUEs) (Best Linear Unbiased Estimators)
即,在所有线性无偏估计值里面,OLS的方差是最小的(因为方差的具体值是随样本变化而变化的,故这里方差最小值的是不管样本如何变化Var(βj^)<Var(β~j)恒成立)。该定理说明了使用OLS估计多元回归模型的合理性。
 求求富哥打赏~QwQ
求求富哥打赏~QwQ



