推断的目的:根基样本估计值来推断真实值
Assumption MLR.6 (Normality of error terms 误差项的正态性)
总体误差u独立于解释变量xi,并且服从正态分布。
ui∼N(0,σ2)
以x不变作为条件,则y的分布也是正态分布
E(y∣x)=E(β0+β1x1+β2x2+...+βkxk+u∣x)=β0+β1x1+β2x2+...+βkxkVar(y∣x)=Var(u∣x)=σ2
所以:
y∣x∼N(β0+β1x1+β2x2+...+βkxk,σ2)y∣x∼N(β0+β1x1+β2x2+...+βkxk,σ2)
MLR.1−MLR.6统称为经典线性假定(CLM),在这个假定下的模型称为经典线性模型,可以证明,在CLM假定下,OLS估计量是最小方差无偏估计量。
定理4.1 正态抽样分布
根据MLR.1−MLR.6:
βj^∼N(βj,Var(βj^))
进一步:
sd(βj^)βj^−βj∼N(0,1)
证明:
由上一章,我们已知:
βj^=βj+∑i=1nr^ij2∑i=1nr^ijui
这是关于ui的线性组合,因为ui服从正态分布,故βj^服从正态分布。
定理4.2 标准化估计量的t分布
根据MLR.1−MLR.6:
se(βj^)βj^−βj∼tn−k−1
证明:
矩阵证明,后续补充。
t分布
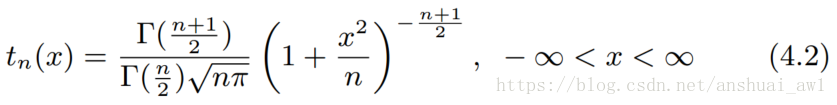
密度函数:

图形为:
如何推断真实值
第一步建立原假设或零假设(Null hypothesis)
H0:βj=0
第二步构建t−statistic(t统计量)
tβj^=se(βj^)βj^
如何原假设H0成立,则:
tβj^=se(βj^)βj^=se(βj^)βj^−βj∼tn−k−1
tβj^是可计算的
假设检验的逻辑:
如果原假设成立,那么t统计量应该服从t分布,我们根据数据计算t统计量,如果t统计量的产生是一个小概率事件,那么拒绝原假设。
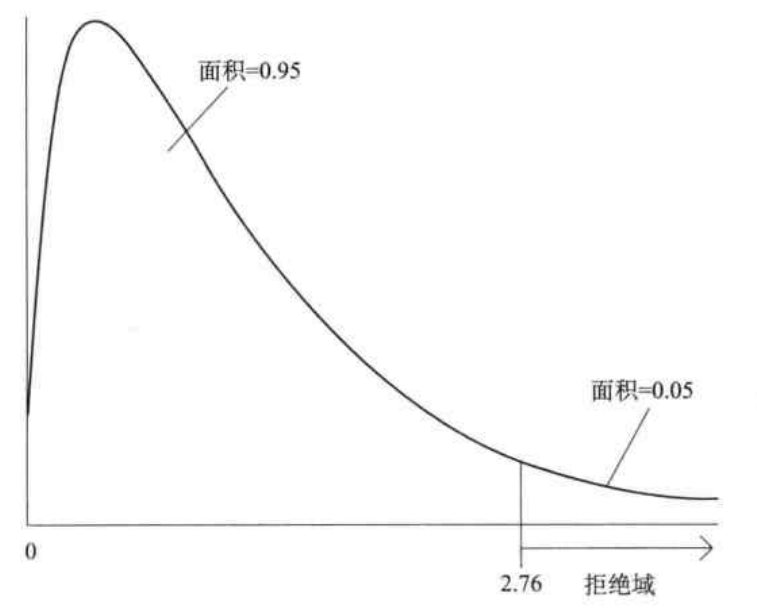
第三步 确定显著性水平和临界值
显著性水平指的是小概率事件发生的概率(当H0正确时拒绝它的概率)。
例如,在5%的显著性水平下,设c为n−k−1的自由度的t分布中处在百分位中第95位的数值,则拒绝法则为
tβj>c
单侧备择假设(Testing against one−sided alternatives)
第一步提出原假设:
Test:H0:βj=0 against H1:βj>0
第二步计算t统计量
第三版根据自由度和显著性水平,计算临界值。
双侧备择假设(Testing against two−sided alternatives)
拒绝法则:
∣tβj^∣>c
如果在一定显著性水平上拒绝H0,我们通常说:xj是统计显著的(statistically significant) ,反之,我们则称"xj在显著性水平为5%时是统计上不显著的(statistically insignificant)"
其他形式的假设
原假设:
H0: βj=aj
t统计量:
t=se(βj^)βj^−aj
计算t检验的p值
p值的含义:给定t统计量的观测值,能拒绝原假设的最小显著性水平
即,显著性(阴影面积)不断减少的过程中,最小的能将t统计量包含住的显著性的值;此时,t统计量是临界值,p为t统计量到无穷处积分出的面积。
实践中,我们往往希望更小的显著性水平(显著性水平越小,拒真错误的可能性越小),因此,p值刻画了样本数据能提供的最优(小)的显著性水平。
在双侧假设下:
p=P(∣T∣>∣t∣)
其中,T为自由度为n−k−1的t分布随机变量,t为该检验统计量的数值。
对于一定的显著性水平α,若p<α,则拒绝原假设;若p>α,则在α的显著性水平下,就不能拒绝H0.
置信区间(Confidence intervals)
置信区间:真实值所在的取值范围
在一定显著性水平下(如0.05),可以求得临界值C0.05,−C0.05(分别是t分布的上下2.5%分位数)
故不能拒绝原假设的区间为:
−C0.05<tβ^<C0.05
−C0.05<se(βj^)βj^−βj<C0.05
从概率角度:
P(−C0.05<se(βj^)βj^−βj<C0.05)=95%
化简得:
P(βj^−C0.05se(βj^)<βj<βj^+C0.05se(βj^))=95%
故在5%的显著性水平下,βj的置信区间为:
(βj^−C0.05se(βj^) , βj^+C0.05se(βj^) )
aj∈/interval => reject H0:βj=aj
检验关于参数的一个线性组合假设
log(wage)=β0+β1jc+β2univ+β3exper+u
如果要检验β1是否显示小于β2,直觉是H0:β1<β2,但此时t统计量为:
t=se(β1^−β2^)β1^−β2^
其分母se(β1^−β2^)无法求得,故考虑换一种方法。
令H0:θ1=0 对H1:θ1<0,将β1=θ1+β2代入原式:
log(wage)=β0+θ1jc+β2(jc+univ)+β3exper+u
用新变量totcoll代替(jc+univ),此时可求得t统计量:
t=se(θ1)θ1
对多个线性约束的检验:F检验
原假设:
H0:βk−q+1=0,βk−q+2=0,...,βk=0
备择假设:
H1: H0 不成立
第一步,估计不受约束模型,计算残差平方和SSRur
y=β0+β1x1+β2x2+...+βkxk+u
即该模型的残差平方和
第二步,估计受约束模型,计算残差平方和SSRr
y=β0+β1x1+β2x2+...+βk−qxk−q+u
即该模型的残差平方和
第三步,比较残差平方和是不是有很大变化,计算F统计量以及做F检验。
F统计量(F−statistic)
F=SSRur/(n−k−1)(SSRr−SSRur)/q∼Fq,n−k−1
其中:q为约束条件的个数
如果拒绝H0,我们就说xk−q+1,...,xk在适当的显著性水平上是联合统计显著的,否则是联合不显著的。
对全部系数检验
H0:β1=β2=...=βk=0
不受约束模型中:
R2=1−SSTSSRur
故:
SSRur=SST(1−R2)
受约束模型中R2=0,故
SSRr=SST
代入化简得:
F=SSRur/(n−k−1)(SSRr−SSRur)/q=(1−R2)/(n−k−1)R2/k∼Fq,n−k−1
此时的显著性称为回归的整体显著性(overall significnace of the regression)
有时,很小的R2会导致高度显著的F统计量,这便解释了我们为什么需要计算F统计量来检验联合显著性,而不是仅仅看一下R2的大小。
 求求富哥打赏~QwQ
求求富哥打赏~QwQ



