Consistency(一致性):
当样本无限增加时,估计值无限接近真实值。
对于 ∀ ϵ>0 ,以及 n→∞,如果
P(∣θn−θ∣<ϵ)→1
那么估计θn是总体参数θ的一致估计,记为 plim θn=θ
定理5.1 OLS的一致性
在假定MLR.1到MLR.4下,对所有j=0,1,...k,OLS估计量βj^都是βj的一致估计,即 plim βj^=βj
对一元回归的证明:
将y1=β0+β1xi1+ui代入β1^,可以化简得:
β1^=∑i=1n(xi1−xˉ1)2∑i=1n(xi1−xˉ1)yi=β1+n−1∑i=1n(xi1−xˉ1)2n−1∑i=1n(xi1−xˉ1)ui
再依据大数定理:
plim(n−1i=1∑n(xi1−xˉ1)2)=Var(x1)
plim(n−1i=1∑n(xi1−xˉ1)ui)=Cov(x1,u)=E(x1u)−E(x1)E(u)=E(x1u)
证明:
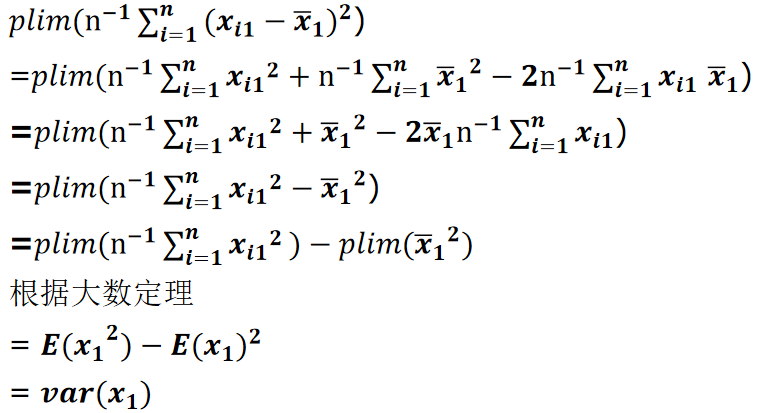
根据假设MLR.4 :E(u∣x)=0,可得Cov(x1,u)=0,故:
plim β^1=β1+Var(x1)Cov(x1,u)=β1
当Cov(x1,u)=0时,就会产生不一致性(Inconsistency), 其偏误值wei
plim β^1−β1=Var(x1)Cov(x1,u)
假定 MLR.4′(零均值和零相关)
对∀j=1,2...k,都有E(u)=0E(u)=0 和 Cov(xj,u)=0Cov(xj,u)=0
对比假定MLR.4 : $\ E(u|x_1,…,x_n)=0 ,可以发现MLR.4’$是一个更弱的假设,因为:
E(u)=0⟹Cov(x1,u)=E(x1u)=EX1(E(x1u∣x1))=EX1(x1E(u∣x1))
(这里运用了期望的迭代法则或者说重期望公式)
由上式,当E(u∣x1)=0,可以推出 Cov(x1,u)=0 和 E(u)=0,反之不成立。故MLR.4是一个更强的假设。
直观上理解:E(u∣x1)=0 以为着u和x1的任意形式都不相关,而Cov(x1,u)=0 仅仅以为这u和x1的一次形式不相关,故E(u∣x1)=0更严格。
遗漏变量的渐近性类似问题
当变量被遗漏时,自变量会被误放到误差项u中,导致其余自变量出现相关性。
真实模型:
y=β0+β1x1+β2x2+v
错误模型:
y=β0+β1x1+[β2x2+v]=β0+β1x1+u
于是:
plim β1^=β1+Var(x1)Cov(x1,u)=β1+β2Var(x1)Cov(x1,x2)=β1+β2δ
渐近正态与大样本推断
定理5.2 (Asymptotic normality of OLS)OLS的渐近正态性
在假设MLR.1−MLR.5下:
se(βj^)β^j−βj∼aN(0,1)sd(βj^)β^j−βj∼aN(0,1)
plim σ^2=σ2
n(βj^−βj)∼aN(0,aj2σ2)
其中,aj2=plim(n−1∑i=1nr^ij2),r^ij是xj对其余自变量进行回归所得到的残差。
该定理表明,无论u的总体分布如何,合理标准化之后的OLS估计量都是近似于服从正态分布的。
在大样本下,OLS估计量的方差估计值:
Var^(βj^)=SSTj(1−Rj2)σ^2 ,j=1,2...k
其中,SSTj依概率收敛于 nVar(xj),
σ^2收敛于σ2 , 1−Rj2 收敛于某一个固定值
所以当样本增加时,n Var^(βj^) 收敛于一个常数,或者说:
Var^(βj^)=n常数
可以说 Var^(βj^)以1/n的速度收敛于0
se(βj^)=n常数
标准误以1/n 的速度收敛于0。
定理5.3 OLS的渐近有效性
i=1∑ngj(xi)(yi−β~0−β~1xi1−...−β~kxik)=0,j=0,1,...k
在高斯-马尔科夫假定下,令βj~表示从求解形如上式的方程所得到的估计量,而βj^表示OLS估计量。那么,对j=0,1,2,...,k,OLS估计量具有最小的渐近方差:
Avarn(βj^−βj)≤Avarn(βj~−βj)
 求求富哥打赏~QwQ
求求富哥打赏~QwQ



