量化投资第三次作业——多因子选股策略
一、综述
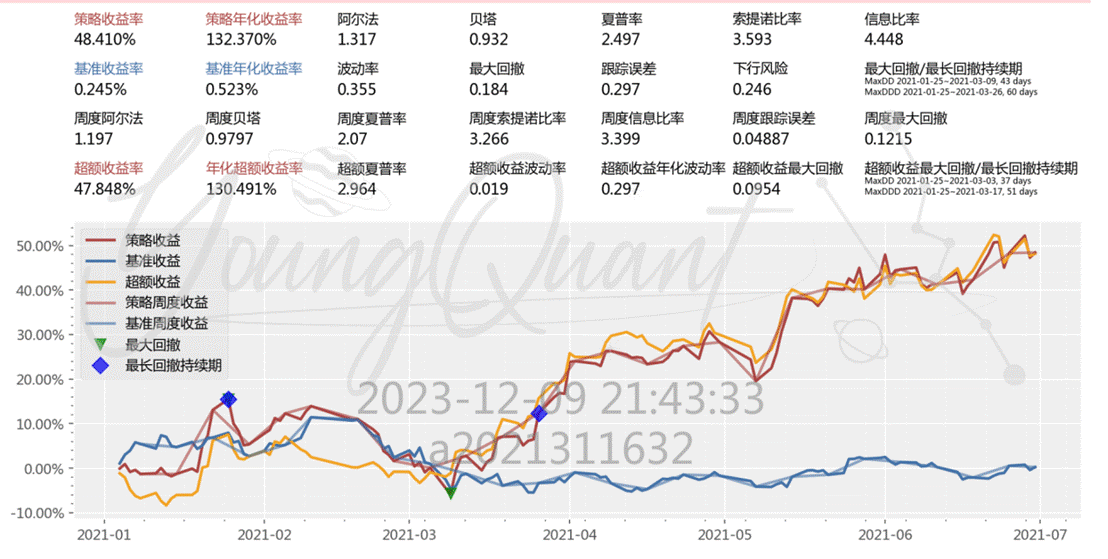
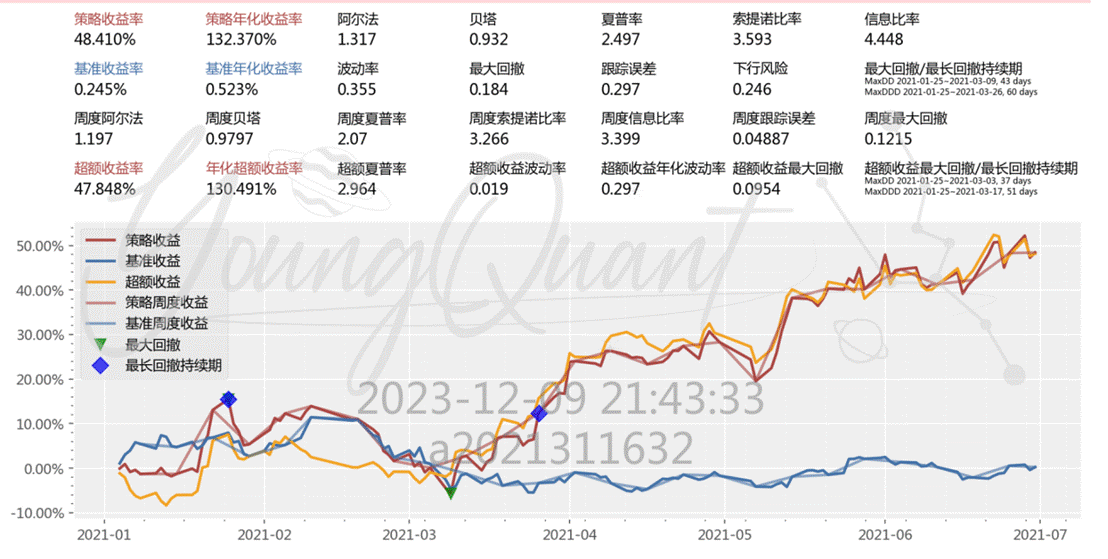
本策略结合了多因子、MACD、止损策略的组合,其中多因子策略中考虑到了五个因子,分别是市值因子、流动性因子、杠杆因子、账面市值比因子、残差波动性因子,下文将会对这五个因子开展具体分析。最后在回测区间2021.1.1−2021.6.30,回测目标为申万行业、医疗服务,最后实现了132%132%的年化收益率。
二、板块选择
在2023年,人们对医疗板块的持续关注不仅是疫情遗留下的影响,更是由于医疗技术的飞速发展和公众健康意识的提升所推动。从2021年疫情爆发开始,医疗板块便成为了市场的焦点。这段时间里,人们对医疗保健的需求显著增加,医疗行业的创新和发展受到了前所未有的重视。尽管疫情已经逐渐得到控制并走向结束,公众对医疗保健的兴趣和关注却并未随之减弱。事实上,这种关注已转化为对医疗行业长期稳定发展的期待。
在这种背景下,我们选择对申万行业的医疗板块进行回测交易,可以更好地理解并把握这一板块未来的发展趋势,为投资决策提供有力的数据支持。
三、因子分析
第一个因子:Size(市值因子)
市值的自然对数因子是指使用自然对数(基数为e)对公司市值进行转换所得到的值。
其中市值通常是指股票的总市值(股价乘以流通股数)。使用自然对数进行转换是为了减少原始数据的偏斜性和缩放差异,使得标的池中的数据更适合统计分析。
作用是降低极端值的影响,比如降低大市值公司对分析结果的影响,使数据更趋于正态分布;同时市值的自然对数因子常被视为一个衡量公司规模的指标,它可以帮助我们策略制定者区分大型公司和小型公司,并据此制定不同的投资策略,比如在模型中我们采用了降序,更加倾向于对大型公司进行投资;市值的自然对数因子也用于调整风险,因为公司规模较大可能意味着更低的相对风险。
小组在构建股票投资组合时,我们将市值的自然对数因子作为筛选或加权的依据,并且在多因子模型中,还把市值的自然对数与其他因子结合,共同决定股票的预期收益,我们更加偏好投资大型公司,所以我们采用降序。
第二个因子:Liquidity(流动性因子)
在模型中我们将流动性因子定义为过去一个月换手率之和的自然对数,具体计算公式如下:
lni=1∑nStVt
其中Vt是t日的交易量,St是 t 日的流通股本。
它降低了极端值的影响。一般来说流动性越高,我们可以进行成本更低效率更高的买卖,而当股票的流动性降低,可能导致难以转手造成的风险加大时,我们迅速出售股票,寻找新的流动性好的优质股票。 在模型中我们将流动性因子作为参考,主要目的是为了平衡收益性和流动性,尤其是在我们进行短时间内大批量的股票交易策略时候流动性因子就更加重要。
第三个因子:Leverage(杠杆因子)
杠杆因子=0.38∗市场杠杆+0.35∗资产负债比+0.27∗账面杠杆
我们从三个方面来考虑杠杆,第一个是市场杠杆,分析的是总债务占市场价值的比重,第二个是资产负债比,分析的是总负债占总资产的比重,第三个是账面杠杆,显示的是公司负债和股东权益的比率。三个杠杆的具体计算公式如下:
市场杠杆(mlev):me是普通股数值,pe是优先股账面价值,ld是长期负债账面价值。
mlev=meme+pe+ld
资产负债比(dtoa):td是总负债账面价值,ta是总资产账面价值。
dtoa=tatd
账面杠杆(blev):be是普通股账面价值,pe是优先股账面价值,ld是长期负债账面价值.
blev=bebe+pe+ld
经过调试和报告,我们将权重分别设置为0.38,0.35,0.27,将更多的重心放在市场杠杆和资产负债比上来衡量财务风险,挑选出风险水平较低的股票。
第四个因子:Book to price(账面市值比因子)
上个季报公司公布的普通股权账面价值(即净资产)除以当前的市值。市值每月更新一次。净资产账面价值每季度更新一次。
从价值投资指标角度来讲,B/M高说明股票被低估了,此时可以考虑买入,B/M低则说明股票被高估了,此时可以考虑卖出。还有风险评估的角度,当B/M高的时候说明市场期望较低,下跌的空间较小,而B/M低说明市场期望过高了,下跌的风险大,尤其是在经济下行阶段,投资该种股票的风险更大。
在本模型中我们使用该因子来寻找被低估的股票,并且结合其他的因子指标进行价值判断。
第五个因子:Residual Volatility(残差波动因子)
残差波动因子衡量了收益率的加权波动性,更加具体的衡量了风险,它直接从股票自身的波动性来判断它的风险,帮助我们识别并且量化不能由市场因素来解释的风险。在本模型中我们通过减少高残差的股票来降低组合的整体风险。具体计算公式如下:
是过去30个交易日的日超额收益率波动率,按照指数加权权重,半衰期为14个交易日。
dastd=n1t=1∑nwt(ret−re)2
三、因子筛选之后的策略:MACD策略和止损
在经过因子筛选之后,我们将五个因子筛选出来的股票进行交集并且置入stock列表中,再进行MACD策略进行判断,如果股票被高估则将股票移出列表,符合MACD信号则予以保留。
最后我们添加了止损策略,本策略的止损判断是当股票价值低于买入时价值的70即触发止损,立刻卖出该股票。
四、历史回测结果对比
这是初始demo的表现:
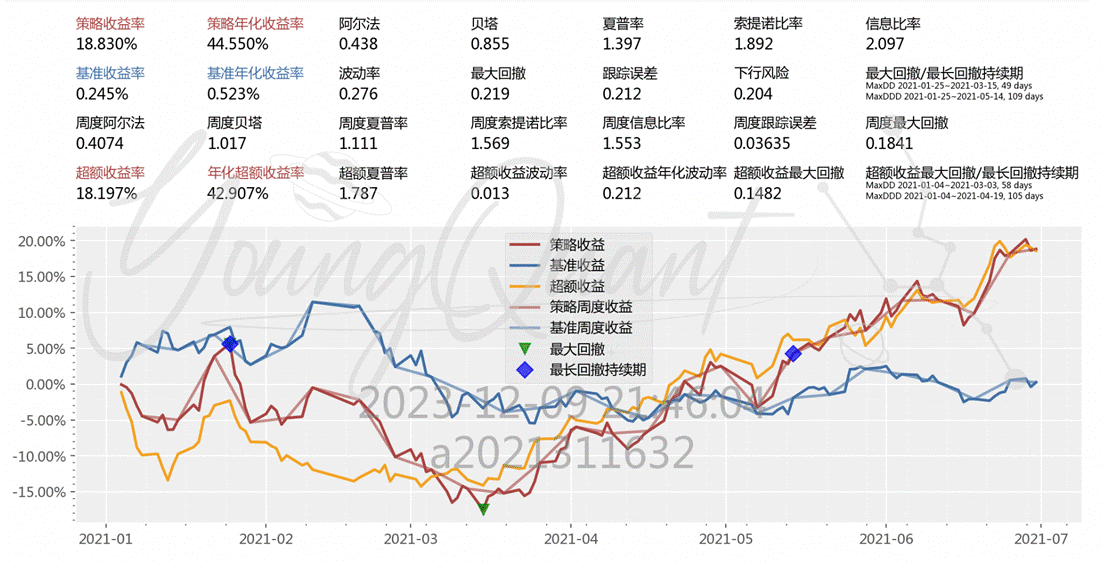
在这之后我们增加了因子分析,将因子分析筛选出来的股票进行交易,发现策略年化收益率从44提升到63;阿尔法从0.438提升到0.627,相较于市场组合有一定优势;夏普比率从1.397提升到1.477,承担风险得到的额外补偿也进一步提升;但是最大回撤也从0.219提升到0.247,下行风险从0.204提升到0.261这说明收益提高的同时风险也有一定上升:
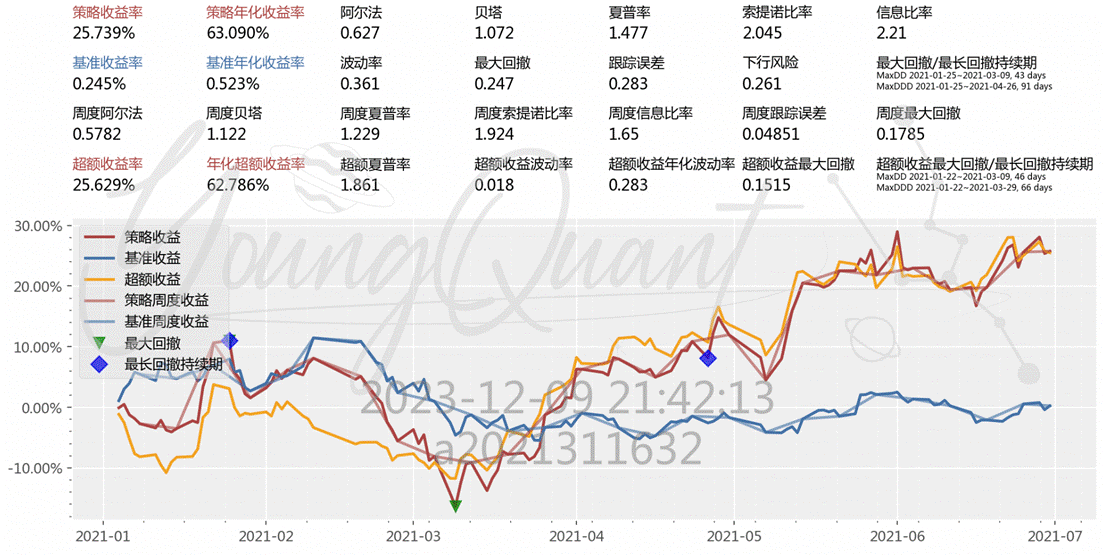
最后我们添加了MACD和止损策略,发现贝塔比率下降,虽然依然高于基础策略,但相较于因子策略,已经从1.072下降到0.932。夏普比率、阿尔法、策略年化收益率均显著提升,比如策略年化收益率从63提升到132;策略的波动率和下行风险均有降低,波动率从0.361降低到0.355,下行风险从0.261降低到0.246,说明在控制风险上起到了不错的效果:
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
| from youngquant.api import *
from youngquant import exec_strategy
from yqdata.services.factor import *
import yqdata.services as yq
import pandas as pd
import numpy as np
import datetime
import statsmodels.api as sm
import warnings
import talib
warnings.filterwarnings('ignore')
config = {
"base": {
"start_date": "2021-01-01",
"end_date": "2021-06-30",
"frequency": "1d",
"benchmark": "000300.XSHG",
"accounts": {
"stock": 1000000
}
},
"extra": {
"log_level": "error",
},
"mod": {
"sys_analyser": {
"enabled": True,
"plot": True
},
"mongodb": {
"enabled": True,
}
}
}
def find_order_stocks(context, bar_dict):
'''
根据选股思路确定本月想下单的股票池,存入context.yq_order_stocks
'''
df_tscodes = yq.concept.sw_detail(index_code='801156.SI')
ts_codes = df_tscodes['con_code']
factors_dict = {}
start_time = (context.now - datetime.timedelta(days=context.observation)).strftime("%Y%m%d")
end_time = context.now.strftime("%Y%m%d")
print('start_time = ',start_time)
print('end_time = ',end_time)
for ts_code in ts_codes:
yq_code = ts_code.replace('SH', 'XSHG').replace('SZ', 'XSHE')
if instruments(yq_code).days_from_listed() > context.observation and not any(is_suspended(yq_code, context.observation)):
Size = yq.basic.daily_basic(ts_code=ts_code, start_date=start_time, end_date=end_time, fields='total_mv')
Log_Size = np.log(Size['total_mv'].mean())
query_body = {
"_source": ["ts_code", "turnover_rate_f", "trade_date"],
"query": {
"bool": {
"must": [
{"match_phrase": {"ts_code": ts_code}},
{"exists": {"field": "turnover_rate_f"}},
{"range": {"trade_date": {"gte": start_time, "lte": end_time}}}
]
}
},
"size": 10000
}
df = yq.common.query(index='daily_basic', body=query_body)
Liquidity = np.log(df["turnover_rate_f"].sum())
dff = get_finance_factor(ts_code=ts_code,start_date=start_time, end_date=end_time,factors='debt_to_asset_ratio_ttm,book_leverage_ttm,market_leverage_ttm')
if not dff.empty:
dff.fillna(0, inplace=True)
DTOA_mean = dff['debt_to_asset_ratio_ttm'].mean()
BLEV_mean = dff['book_leverage_ttm'].mean()
MLEV_mean = dff['market_leverage_ttm'].mean()
Leverage = 0.35*DTOA_mean+0.27*BLEV_mean+0.38*MLEV_mean
else:
Leverage = 0
df_btop = yq.basic.daily_basic(ts_code=ts_code, start_date=start_time, end_date=end_time, fields='ts_code,pb')
df_btop['btop']= 1/df_btop['pb']
Book_to_price =df_btop['btop'].mean()
df = pd.DataFrame()
df_var = yq.basic.daily_basic(ts_code=ts_code, start_date=start_time, end_date=end_time, fields='close')
df['daily_return'] = df_var['close'].pct_change()
df = df.drop(df.index[0])
halflife = 12
ewma = df['daily_return'].ewm(halflife=halflife).mean()
Residual_Volatility = np.sum(((df['daily_return'] - ewma) ** 2) * np.exp(-np.arange(len(df)) / halflife)) / np.sum(np.exp(-np.arange(len(df)) / halflife))
factors_dict[ts_code] = {'Size':Log_Size,'Liquidity':Liquidity,'Book_to_price': Book_to_price,'Leverage': Leverage,'Volatility': Residual_Volatility}
factors_df = pd.DataFrame(factors_dict).T
factors_df['Size_rank'] = factors_df['Size'].rank(ascending=False)
factors_df['Leverage_rank'] = factors_df['Leverage'].rank()
factors_df['Liquidity_rank'] = factors_df['Liquidity'].rank(ascending=False)
factors_df['Book_to_price_rank'] = factors_df['Book_to_price'].rank(ascending=False)
factors_df['Volatility_rank'] = factors_df['Volatility'].rank(ascending=False)
topM, topN = context.topM, context.topN
alternative_stocks = factors_df.query('Volatility_rank < @topM & Size_rank < @topM & Book_to_price_rank < @topM & Liquidity_rank < @topM & Leverage_rank < @topM' )
alternative_stocks['total_rank'] = alternative_stocks[['Size_rank', 'Book_to_price_rank', 'Liquidity_rank','Leverage_rank','Volatility_rank']].mean(axis=1).rank()
order_stocks = alternative_stocks.query('total_rank < @topN').index
context.yq_order_stocks = [stock.replace('SH','XSHG').replace('SZ','XSHE') for stock in order_stocks]
SHORTPERIOD = 12
LONGPERIOD = 26
SMOOTHPERIOD = 9
OBSERVATION = 200
for stock in context.yq_order_stocks:
pricefilter = history_bars(stock,OBSERVATION,'1d','close',adjust_type='pre')
macd, signal, hist = talib.MACD(pricefilter, SHORTPERIOD, LONGPERIOD, SMOOTHPERIOD)
if macd[-1] - signal[-1] < 0:
context.yq_order_stocks.remove(stock)
def sink_stock(context, bar_dict):
'''卖出本月未入选的股票,买入新入选的股票'''
stock_to_sell = set(context.portfolio.positions) - set(context.yq_order_stocks)
target_percent = 1 / len(context.yq_order_stocks)
for stock in stock_to_sell:
order_target_percent(stock, 0)
for stock in context.yq_order_stocks:
order_target_percent(stock, target_percent)
def price_in(context,bar_dict):
'''用上一交易日的收盘价近似本月第一个交易日的开盘价,即成交价'''
data0=[]
for stock in context.yq_order_stocks:
open0=history_bars(stock,1,'1d','close',adjust_type='pre')
data0.append(open0)
context.data0=data0
def stop_losing(context,bar_dict):
'''止损'''
for i in range(len(context.yq_order_stocks)):
lossdata=history_bars(context.yq_order_stocks[i],1,'1d','close',adjust_type='pre')
if lossdata < context.data0[i]*0.7:
order_target_percent(context.yq_order_stocks[i], 0)
def initialize(context):
context.observation = 30
context.topM = 200
context.topN = 10
scheduler.run_monthly(find_order_stocks, tradingday=1, time_rule='before_trading')
scheduler.run_monthly(sink_stock, tradingday=1, time_rule=market_open(hour=0))
scheduler.run_monthly(price_in,tradingday=1)
scheduler.run_daily(stop_losing)
def handle_data(context, bar_dict):
pass
exec_strategy(initialize=initialize, handle_data=handle_data, config=config)
|
 求求富哥打赏~QwQ
求求富哥打赏~QwQ



